AI Papers Collection
I've collected the papers here, along with some key takeaways from each. They are in chronological order to make it easier to see how they build on each other. Most are papers, but a few are books, blog posts, course notes, etc. In any case, it's a lot of reading! I've highlighted a few that I think are particularly worth a look.
- 1993 - Keeping Neural Networks Simple By Minimizing the Description Length of the Weights
- 2004 - A Tutorial Introduction to the Minimum Description Length Principle
- 2008 - Machine Super Intelligence
- 2011 - The First Law of Complexodynamics
- 2012 - ImageNet Classification with Deep Convolutional Neural Networks
- 2014 - Neural Turing Machines
- 2014 - Quantifying the Rise and Fall of Complexity in Closed Systems
- 2015 - Deep Residual Learning for Image Recognition
- 2015 - Neural Machine Translation by Jointly Learning to Align and Translate
- 2015 - Pointer Networks
- 2015 - Recurrent Neural Network Regularization
- 2015 - The Unreasonable Effectiveness of Recurrent Neural Networks
- 2015 - Understanding LSTM Networks
- 2016 - Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
- 2016 - Identity Mappings in Deep Residual Networks
- 2016 - Multi-Scale Context Aggregation by Dilated Convolutions
- 2016 - Order Matters: Sequence to sequence for sets
- 2016 - Variational Lossy Autoencoder
- 2017 - A Simple Neural Network Module for Relational Reasoning
- 2017 - Attention is All You Need
- 2017 - Kolmogorov Complexity and Algorithmic Randomness
- 2017 - Neural Message Passing for Quantum Chemistry
- 2018 - Relational Recurrent Neural Networks
- 2019 - GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
- 2020 - Scaling Laws for Neural Language Models
- 2024 - CS231n Convolutional Neural Networks for Visual Recognition
Keeping Neural Networks Simple by Minimizing the Description Length of the Weights
"Supervised neural networkler, weightlerindeki bilgi miktarı training caselerinin output vektörlerindeki bilgiden çok daha az olduğunda iyi genelleme yaparlar. Bu nedenle öğrenme sırasında, weightlerin içerdiği bilgi miktarını cezalandırarak weightleri basit tutmak önemlidir. Bir weight'teki bilgi miktarı, Gaussian noise eklenerek kontrol edilebilir ve gürültü seviyesi, networkteki beklenen kare hatası ile weightlerdeki bilgi miktarı arasındaki dengeyi optimize etmek için öğrenme sırasında ayarlanabilir. Non-linear hidden unitler içeren bir networkte beklenen kare hatanın ve gürültülü weightlerdeki bilgi miktarının türevlerini hesaplama yöntemini açıklıyoruz. Output unitler linear olduğunda, türevler zaman alıcı Monte Carlo simülasyonları olmadan verimli bir şekilde hesaplanabilir. Bir neural networkün weightlerini iletmek için gereken bilgi miktarını minimize etme fikri, weightleri kodlamak için bir dizi ilginç şema ortaya çıkarır."
Minimum Description Length Principle, bazı verilerin en iyi modelinin, model açıklamasının uzunluğu ile bu model kullanılarak kodlanmış verilerin uzunluğunun toplamını minimize eden model olduğunu belirtir.
- MDL prensibini neural networklere uygulayarak model karmaşıklığını kontrol eder ve overfittingi önler.
- Weight-sharing kullanarak weightlerin description lengthini minimize eder: Aynı weight, ağdaki birden fazla bağlantıya uygulanarak, serbest parametre sayısını ve dolayısıyla model karmaşıklığını azaltır.
A Tutorial Introduction to the Minimum Description Length Principle
Minimum Description Length Principle ve bunun model seçimine uygulamalarına açıkça yazılmış bir giriş.
- Veri sıkıştırma olarak öğrenme Verilerdeki her düzenlilik, bu verileri sıkıştırmak için kullanılabilir ve öğrenme, bu düzenlilikleri bulmakla eşdeğer tutulabilir.
- Model seçimi olarak MDL En iyi model, modelin açıklamasının uzunluğu ile bu model kullanılarak kodlanmış verilerin uzunluğunun toplamını minimize eden modeldir.
Machine Super Intelligence
Bu tez, bir agent'ın zeki olmasının ne anlama geldiğini tanımlamayı amaçlar. Zekânın resmi olmayan tanımlarından başlayarak, zekâyı matematiksel olarak genel, güçlü ve zarif bir şekilde tanımlar. Bu, bilinmeyen bir ortamla etkileşime girerek beklenen ödülünü maksimize eden optimal bir ajan kavramına yol açar. Pratik bir teori olmasa da – tanımları hesaplanabilir değildir – gerçek, optimal olmayan ajanları anlamak için teorik bir çerçeve sağlayabilir.
- "Zekâ, bir agent'ın çok çeşitli ortamlarda hedeflere ulaşma yeteneğini ölçer."
- Bir ortamın complexity'si, ortamın davranışını üreten en kısa programın uzunluğudur (Kolmogorov complexity ).
- Bir ortamın öncül olasılığı, karmaşıklığı ile üstel olarak azalır (Algorithmic probability ). Bu, Occam'ın usturasını resmileştirir.
- Bir agent'ın Universal Intelligence'ı, ödüllerinin beklenen değeridir.
- Mükemmel veya "universal agents", herhangi bir hesaplanabilir ortamda beklenen ödüllerini maksimize eder. Hesaplanabilir olmasa da (çünkü Kolmogorov complexity hesaplanamaz), hesaplanabilir ajanların zekâsı üzerinde teorik bir üst sınır sağlar.
The First Law of Complexodynamics
Teorik bilgisayar bilimcisi Scott Aaronson (complexity theory, quantum computing), "complex systems" ile ne kastettiğimizi belirlemeye çalışır ve karmaşıklığı titiz bir şekilde tanımlamanın ne anlama geleceği hakkında tahminlerde bulunur. Entropi ve (kaynak-sınırlı) Kolmogorov complexity gibi kavramları bir araya getirir. Burada bazı ilginç sorular var, ancak pratik çıkarımlar arıyorsanız bunu atlayabilirsiniz.
ImageNet Classification with Deep Convolutional Neural Networks
"Biz 1.2 milyon yüksek çözünürlüklü görüntüyü ImageNet LSVRC-2010 yarışmasında 1000 farklı sınıfa ayırmak için büyük, derin bir convolutional neural network eğittik. Test verileri üzerinde, önceki state-of-the-art'a göre önemli ölçüde daha iyi olan %37.5 ve %17.0 top-1 ve top-5 hata oranları elde ettik. 60 milyon parametre ve 650.000 nöron içeren neural network, beş convolutional layer'dan oluşmaktadır, bunların bazılarını max-pooling layer'lar takip etmekte ve son olarak 1000 yönlü softmax ile üç fully-connected layer bulunmaktadır. Eğitimi hızlandırmak için, doymayan nöronlar ve konvolüsyon işleminin çok verimli bir GPU implementasyonu kullandık. Fully-connected layer'larda overfitting'i azaltmak için son zamanlarda geliştirilen ve çok etkili olduğu kanıtlanan "dropout" adlı bir regularization metodu kullandık. Ayrıca bu modelin bir varyasyonunu ILSVRC-2012 yarışmasına soktuk ve ikinci en iyi girişin elde ettiği %26.2'ye kıyasla %15.3'lük kazanan bir top-5 test hata oranı elde ettik."
- AlexNet, bir deep convolutional neural network tanıttı ve image classification'da benzeri görülmemiş bir performans elde etti. AlexNet, 2012'de ImageNet Large Scale Visual Recognition Challenge'ı önemli bir farkla kazanarak, deep learning'i bilgisayarla görü araştırmalarının ön saflarına taşıdı.
- Derin Mimari AlexNet'in derinliği – beş convolutional ve üç fully connected layer – ağın hiyerarşik özellik temsilleri öğrenmesine olanak tanıdı ve daha sığ mimarilerle mümkün olmayan verilerdeki karmaşık örüntüleri yakaladı.
- GPU'larla Eğitim Eğitimi hızlandırmak için GPU'lar, paralel hesaplama ve ReLU aktivasyon fonksiyonları kullanıldı.
Neural Turing Machines
"Neural network'lerin yeteneklerini, attentional process'ler aracılığıyla etkileşime girebilecekleri harici bellek kaynaklarına bağlayarak genişletiyoruz. Birleştirilmiş sistem, bir Turing Makinesi veya Von Neumann mimarisine benzer, ancak uçtan uca diferansiyellenebilir olup, gradient descent ile verimli bir şekilde eğitilebilmesine olanak tanır. İlk sonuçlar, Neural Turing Machine'lerin kopyalama, sıralama ve ilişkisel hatırlama gibi basit algoritmaları girdi ve çıktı örneklerinden çıkarabildiğini göstermektedir."
- Neural Turing Machine'ler, kendi programlamalarını öğrenen tamamen diferansiyellenebilir bilgisayarlardır. Diferansiyellenebilirlik, NTM'leri gradient descent ile verimli bir şekilde eğitmenin anahtarıdır.
- Bir NN'i harici bellek ile güçlendirmek, klasik RNN'lerin önemli bir sınırlamasını ele alır: bilgiyi uzun süre saklama yetersizliği.
- Daha önceki çalışmalar, RNN'lerin Turing Complete olduğunu, yani prensipte örneklerden algoritmaları öğrenme kabiliyetine sahip olduklarını gösterdi, ancak bunu gerçekte nasıl yapacaklarını göstermedi.
Quantifying the Rise and Fall of Complexity in Closed Systems
"Entropinin monoton olarak artmasının aksine, kapalı sistemlerin "karmaşıklığı" veya "ilginçliği" sezgisel olarak önce artıyor ve sonra denge durumuna yaklaştıkça azalıyor görünmektedir. Örneğin, evrenimiz Büyük Patlama'da karmaşık yapılardan yoksundu ve kara delikler buharlaştıktan ve parçacıklar dağıldıktan sonra da bunlardan yoksun olacak. Bu makale, bu modeli nicelendirmek için ilk girişimde bulunuyor. Model sistem olarak, iki sıvının ("kahve" ve "krema") karışımını simüle eden basit, iki boyutlu bir hücresel otomat kullanıyoruz. Makul bir karmaşıklık ölçüsü, otomatın durumunun kaba taneli bir yaklaşımının Kolmogorov karmaşıklığıdır; buna "görünür karmaşıklık" diyoruz. Bu karmaşıklık ölçüsünü inceliyoruz ve sıvı parçacıkları etkileşime girmediğinde karmaşıklığın asla büyük olmadığını analitik olarak gösteriyoruz. Buna karşılık, parçacıklar etkileşime girdiğinde, karmaşıklığın "kahve fincanının" yatay boyutuna benzer bir maksimuma ulaştığına dair sayısal kanıtlar sunuyoruz. Bu davranışı analitik olarak kanıtlama problemini ortaya koyuyoruz."
Bu makale, The First Law of Complexodynamics makalesindeki fikirleri devam ettiriyor. Bence bunu güvenle atlayabilirsiniz.
- Bir n-bit dizinin entropisi genellikle Kolmogorov complexity ile tanımlanır, yani diziyi üreten en kısa programın uzunluğu ile.
- Kolmogorov complexity'nin hesaplanamaz olduğu iyi bilinir (halting problem ile eşdeğer), ancak belki yaklaşık olarak hesaplanabilir? "Kolmogorov complexity ve sophistication, entropi ve karmaşıklık fikirlerimizi modellemek için yararlı teorik kavramlar olsa da, ikisi de hesaplanamaz olduğundan sayısal simülasyonlarda doğrudan uygulanamaz."
Deep Residual Learning for Image Recognition
"Daha derin neural network'leri eğitmek daha zordur. Daha önce kullanılanlardan önemli ölçüde daha derin olan ağların eğitimini kolaylaştırmak için bir residual learning framework sunuyoruz. Layer'ları, referanssız fonksiyonlar öğrenmek yerine, layer girişlerine referansla residual function'ları öğrenmek üzere açıkça yeniden formüle ediyoruz. Bu residual network'lerin optimize edilmesinin daha kolay olduğunu ve önemli ölçüde artan derinlikten doğruluk kazanabileceğini gösteren kapsamlı ampirik kanıtlar sunuyoruz. ImageNet veri setinde, 152 layer derinliğe kadar olan residual network'leri değerlendiriyoruz - VGG ağlarından 8 kat daha derin ama yine de daha düşük karmaşıklığa sahip. Bu residual network'lerin bir ensemble'ı, ImageNet test setinde %3.57 hata elde ediyor. Bu sonuç, ILSVRC 2015 classification görevinde 1. sırayı kazandı. Ayrıca CIFAR-10 üzerinde 100 ve 1000 layer'lı analizler de sunuyoruz. Temsillerin derinliği, birçok görsel tanıma görevi için merkezi öneme sahiptir. Sadece son derece derin temsillerimiz sayesinde, COCO nesne algılama veri setinde %28'lik göreceli bir iyileştirme elde ediyoruz. Deep residual network'ler, ILSVRC ve COCO 2015 yarışmalarına yaptığımız başvuruların temelini oluşturuyor; burada ayrıca ImageNet detection, ImageNet localization, COCO detection ve COCO segmentation görevlerinde de 1. sıraları kazandık."
- Degradation Problem: Ek layer'lar hem test hem de eğitim hatasını artırabilir, yani sadece overfitting değil. Bu sezgiye aykırıdır çünkü daha derin ağlar, bazı layer'ları identity function olarak ayarlayarak daha sığ ağları temsil edebilir.
- Residual Networks (ResNet)'i tanıtıyor. Temel fikir, bir veya daha fazla layer'ı atlayan ve böylece layer'ların F(x) = H(x) - x residual function'ını temsil etmesini sağlayan skip connection'lardır.
Neural Machine Translation by Jointly Learning to Align and Translate
"Neural machine translation makine çevirisi için yakın zamanda önerilen bir yaklaşımdır. Geleneksel istatistiksel makine çevirisinin aksine, neural machine translation, çeviri performansını en üst düzeye çıkarmak için birlikte ayarlanabilen tek bir neural network oluşturmayı amaçlar. Neural machine translation için son zamanlarda önerilen modeller genellikle encoder-decoder ailesine aittir ve bir kaynak cümleyi, bir decoder'ın çeviri oluşturduğu sabit uzunluklu bir vektöre kodlayan bir encoder'dan oluşur. Bu makalede, sabit uzunluklu bir vektör kullanımının bu temel encoder-decoder mimarisinin performansını artırmada bir darboğaz olduğunu tahmin ediyor ve bir modelin, bu parçaları açıkça sert bir segment olarak oluşturmak zorunda kalmadan, bir hedef kelimeyi tahmin etmek için kaynak cümlenin ilgili kısımlarını otomatik olarak (yumuşak) aramasına izin vererek bunu genişletmeyi öneriyoruz. Bu yeni yaklaşımla, İngilizce-Fransızca çevirisi görevinde mevcut state-of-the-art cümle tabanlı sisteme benzer bir çeviri performansı elde ediyoruz. Ayrıca, nitel analiz, model tarafından bulunan (yumuşak) hizalamaların sezgimizle iyi uyuştuğunu ortaya koyuyor."
- Attention Mechanism'i tanıtıyor, makine çevirisi ve diğer birçok sequence-to-sequence görevinde önemli bir atılım. Attention mekanizması, modelin hedef cümledeki her kelimeyi oluştururken kaynak cümlenin farklı bölümlerine odaklanmasına olanak tanıyarak, önceki encoder-decoder mimarilerindeki sabit uzunluklu bağlam vektörlerinin sınırlamalarını ele alır.
Pointer Networks
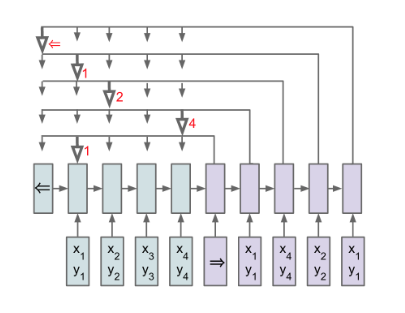
"Öğeleri bir giriş dizisindeki konumlara karşılık gelen ayrık token'lar olan bir çıktı dizisinin koşullu olasılığını öğrenmek için yeni bir neural architecture sunuyoruz. Bu tür problemler, mevcut sequence-to-sequence ve Neural Turing Machines gibi yaklaşımlarla kolayca ele alınamaz, çünkü çıktının her adımındaki hedef sınıfların sayısı, değişken olan girişin uzunluğuna bağlıdır. Değişken boyutlu dizileri sıralama ve çeşitli kombinatoryal optimizasyon problemleri bu sınıfa aittir. Modelimiz, değişken boyutlu çıktı sözlükleri problemini yakın zamanda önerilen neural attention mekanizmasını kullanarak çözer. Daha önceki attention girişimlerinden farkı, her decoder adımında bir encoder'ın gizli birimlerini bir bağlam vektörüne karıştırmak için attention kullanmak yerine, çıktı olarak giriş dizisinin bir üyesini seçmek için bir işaretçi olarak attention kullanmasıdır. Bu mimariye bir Pointer Net (Ptr-Net) diyoruz. Ptr-Net'lerin, yalnızca eğitim örneklerini kullanarak üç zorlu geometrik probleme - düzlemsel konveks gövdeleri bulma, Delaunay üçgenlemelerini hesaplama ve düzlemsel Gezgin Satıcı Problemi - yaklaşık çözümler öğrenmek için kullanılabileceğini gösteriyoruz. Ptr-Net'ler sadece giriş dikkatli sequence-to-sequence'ı geliştirmekle kalmaz, aynı zamanda değişken boyutlu çıktı sözlüklerine genelleme yapmamıza da olanak tanır. Öğrenilen modellerin, eğitildikleri maksimum uzunlukların ötesine genelleştirdiğini gösteriyoruz. Bu görevlerdeki sonuçlarımızın, ayrık problemler için neural öğrenmenin daha geniş bir şekilde keşfedilmesini teşvik edeceğini umuyoruz."
- Değişken Çıktı Sözlükleri: Çıktının her adımındaki hedef sınıfların sayısı, değişken olan girişin uzunluğuna bağlıdır. Geleneksel sequence-to-sequence modelleri sabit bir çıktı kelime dağarcığı gerektirir.
- Çıktının her adımında, model çıktı olarak giriş dizisinin bir üyesini seçmek için girişler üzerinde attention'ı bir işaretçi olarak kullanır. Bu, modelin değişken boyutlu çıktı sözlüklerine genelleme yapmasına olanak tanır.
Recurrent Neural Network Regularization
"Uzun Kısa Süreli Bellek (LSTM) birimleri ile Recurrent Neural Networks (RNN'ler) için basit bir regularization tekniği sunuyoruz. Neural networklerini düzenlemek için en başarılı teknik olan dropout, RNN'ler ve LSTM'ler ile iyi çalışmaz. Bu makalede, dropout'un LSTM'lere nasıl doğru şekilde uygulanacağını gösteriyor ve bunun çeşitli görevlerde aşırı uyumu önemli ölçüde azalttığını gösteriyoruz. Bu görevler arasında dil modelleme, konuşma tanıma, görüntü başlığı oluşturma ve makine çevirisi yer alır."
- Dropout'u yalnızca RNN'lerin bağlantılarının bir alt kümesine uygular.
- "Tekrarlayan bağlantılarda dropout kullanmayarak, LSTM değerli hafıza yeteneğinden ödün vermeden dropout düzenlemesinden yararlanabilir."
The Unreasonable Effectiveness of Recurrent Neural Networks
OpenAI'nin kurucu ortaklarından birinin bu blog yazısı, dizi modellemesi için Recurrent Neural Networks (RNN'ler) gücüne harika bir giriştir. RNN'lerin aldatıcı bir şekilde basit olduğunu gösterir ve RNN'lerin yalnızca karakterden karaktere tahminler kullanarak makul metin oluşturma gücünü gösterir. Üretken dil modellerinin birkaç yıl önce nerede olduğunu ve o zamandan beri ne kadar ilerlediğini görmek eğlenceli.
- "Vanilla neural networkleri eğitmek fonksiyonlar üzerinde optimizasyonsa, recurrent networkleri eğitmek programlar üzerinde optimizasyondur."
- Feed-Forward Neural Networks, sabit boyutlu girişler ve sabit boyutlu çıkışlarla sınırlıdır.
- RNN'ler keyfi uzunluktaki diziler üzerinde çalışır, bu da onları konuşma tanıma, dil modelleme ve makine çevirisi için uygun hale getirir.
Understanding LSTM Networks
Anthropic'in kurucu ortaklarından birinin bu blog yazısı, Long Short-Term Memory (LSTM) networks adı verilen önemli bir RNN türüne harika bir giriştir. Adım adım bir şekilde, bir LSTM biriminin farklı "gate"lerinin bilgiyi depolamak ve almak için nasıl birlikte çalıştığını açıklar.
- LSTM'ler, bilgiyi uzun süre depolayabilen memory cell adı verilen bir gizli durum ekleyerek RNN'leri geliştirir. Bu, uzun dizilerden öğrenme yeteneklerini artırır ve onları doğal dil işleme için uygun hale getirir. Buna karşılık, normal RNN'ler, diyelim ki bir cümlede birbirinden uzak olan kelimeler gibi ayrı bilgi parçalarını bağlamakta zorlanır.
- Bir LSTM birimi, bilginin memory cell'e girişini ve çıkışını düzenleyen bir memory cell, bir input gate, bir output gate ve bir forget gate içerir.
- 1997'den bir fikrin (LSTM'ler) 2015'te araştırma faaliyetinin ön saflarına dönmesini görmek ilginçtir. Bu 18 yılda, hesaplama gücündeki oldukça dramatik artışlar da dahil olmak üzere pek çok şey oldu.
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
"End-to-end deep learning yaklaşımının İngilizce veya Mandarin Çincesi konuşmasını tanımak için kullanılabileceğini gösteriyoruz - birbirinden çok farklı iki dil. El ile tasarlanmış bileşenlerden oluşan tüm pipeline'ları neural network'lerle değiştirdiği için, end-to-end learning gürültülü ortamlar, aksanlar ve farklı diller dahil çeşitli konuşmaları ele almamıza olanak tanır. Yaklaşımımızın anahtarı, daha önce haftalar süren deneylerin şimdi günler içinde çalışmasını sağlayan HPC tekniklerini uygulamamızdır. Bu, üstün mimariler ve algoritmalar belirlemek için daha hızlı iterasyon yapmamıza olanak tanır. Sonuç olarak, birçok durumda, sistemimiz standart veri setlerinde insan çalışanların transkripsiyonu ile rekabet edebilir durumdadır. Son olarak, data center'daki GPU'larla Batch Dispatch adlı bir teknik kullanarak, sistemimizin ölçekli kullanıcılara hizmet verirken düşük gecikme süresiyle çevrimiçi bir ortamda uygun maliyetle devreye alınabileceğini gösteriyoruz."
- End-to-End Learning el ile tasarlanmış bileşenlerden oluşan tüm pipeline'ları (özellikler, akustik modeller, dil modelleri vb.) neural network'lerle değiştirir. Bu, iki çok farklı dil üzerinde gösterilmiştir: İngilizce ve Mandarin.
- Yüksek düzeyde optimize edilmiş eğitim sistemi 8 veya 16 GPU ile.
- Modeller yaklaşık 100 milyon parametre içerir.
Identity Mappings in Deep Residual Networks
"Deep residual network'ler, etkileyici doğruluk ve güzel yakınsama davranışları gösteren son derece derin mimariler olarak ortaya çıkmıştır. Bu makalede, residual building block'ların arkasındaki yayılma formülasyonlarını analiz ediyoruz , bu da identity mapping'leri skip connection'lar ve ekleme sonrası aktivasyon olarak kullanırken, ileri ve geri sinyallerin bir bloktan diğer herhangi bir bloğa doğrudan yayılabileceğini gösteriyor. Bir dizi ablasyon deneyi, bu identity mapping'lerin önemini destekliyor. Bu bizi, eğitimi kolaylaştıran ve genellemeyi iyileştiren yeni bir residual unit önermeye teşvik ediyor. CIFAR-10 (%4.62 hata) ve CIFAR-100 üzerinde 1001 katmanlı bir ResNet ve ImageNet üzerinde 200 katmanlı bir ResNet kullanarak iyileştirilmiş sonuçlar bildiriyoruz."
- Yazarlar, önceki makaleleri olan Deep Residual Learning for Image Recognition üzerine inşa ederek, orijinal residual unit'in bazı kısımlarını identity mapping'lere ayarlayarak yeni bir residual unit öneriyorlar. Sonuç, her katman çifti arasında ileri ve geri sinyallere güzel, ekleyici bir yapı sağlayan bir "residual ilişkisi"dir.
- 1001 katmanlı bir ResNet'te yeni residual unit'leri gösteriyor.
Multi-Scale Context Aggregation by Dilated Convolutions
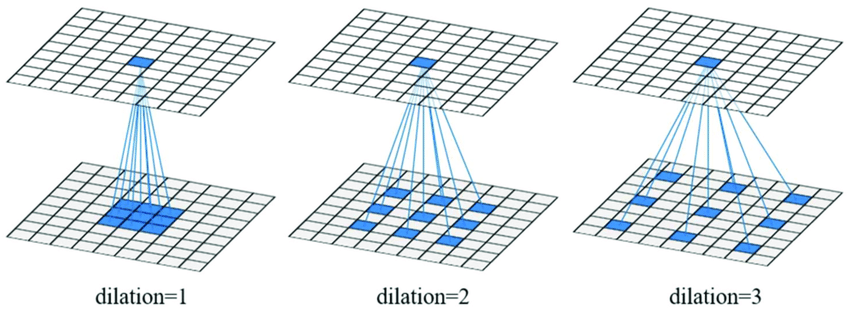
Semantic segmentation(anlamsal bölütleme) için state-of-the-art modeller, orijinalinde image classification için tasarlanmış olan convolutional network'lerin adaptasyonlarına dayanmaktadır. Ancak, yoğun tahmin ve görüntü sınıflandırması yapısal olarak farklıdır. Bu çalışmada, özellikle yoğun tahmin için tasarlanmış yeni bir convolutional network modülü geliştiriyoruz . Sunulan modül, çözünürlük kaybetmeden çok ölçekli bağlamsal bilgileri sistematik olarak toplamak için dilated convolution'ları kullanır. Mimari, dilated convolution'ların çözünürlük veya kapsam kaybı olmadan alıcı alanın üstel genişlemesini desteklediği gerçeğine dayanmaktadır. Sunulan bağlam modülünün state-of-the-art semantic segmentation sistemlerinin doğruluğunu artırdığını gösteriyoruz. Ayrıca, image classification ağlarının yoğun tahmine adaptasyonunu inceliyor ve adapte edilen ağı basitleştirmenin doğruluğu artırabileceğini gösteriyoruz.
- Semantic segmentation görüntüdeki her piksele bir etiket atar. Bu, tüm görüntüye tek bir etiket atamayı amaçlayan image classification'dan farklı bir görevdir. Bununla birlikte, birçok semantic segmentation modeli, image classification için tasarlanmış mimarilere dayanmaktadır.
- Image classification'dan ödünç alınan teknikleri kritik olarak değerlendirir ve pooling ve subsampling katmanlarının semantic segmentation için iyi bir uyum olmayabileceğini bulur.
- Çekirdek elemanları arasında boşluklar olan bir konvolüsyon türü olan dilated convolution'ları savunur. Bu, parametre sayısını artırmadan alıcı alanı genişletir.
Order Matters: Sequence to sequence for sets
"Diziler, recurrent neural networkların yeniden ortaya çıkışı sayesinde supervised learning'de birinci sınıf vatandaşlar haline gelmiştir. Bir dizi gözlemden veya gözleme haritalama gerektiren birçok karmaşık görev, artık dizilerin ortak olasılığını verimli bir şekilde temsil etmek için chain rule kullanan sequence-to-sequence (seq2seq) çerçevesiyle formüle edilebilir. Ancak, birçok durumda, değişken boyutlu girdiler ve/veya çıktılar doğal olarak diziler şeklinde ifade edilemeyebilir. Örneğin, görevi onları sıralamak olan bir modele bir dizi sayıyı nasıl gireceğimiz açık değildir; benzer şekilde, çıktılar random variable'lara karşılık geldiğinde ve görev bunların bilinmeyen joint probability'sini modellemek olduğunda, çıktıları nasıl düzenleyeceğimizi bilmiyoruz. Bu makalede, öncelikle çeşitli örnekler kullanarak, altta yatan bir modeli öğrenirken girdi ve/veya çıktı verilerini düzenlediğimiz sıranın önemli ölçüde önemli olduğunu gösteriyoruz. Ardından, seq2seq çerçevesinin ötesine geçen ve girdi setlerini ilkeli bir şekilde ele alan bir uzantıyı tartışıyoruz. Ayrıca, eğitim sırasında olası sıralar üzerinde arama yaparak, çıktı kümelerinin yapı eksikliğiyle başa çıkan bir loss öneriyoruz. Sıralamaya ilişkin iddialarımızın ampirik kanıtlarını ve seq2seq çerçevesindeki değişiklikleri, benchmark language modeling ve parsing görevlerinin yanı sıra iki yapay görev üzerinde - sayıları sıralama ve bilinmeyen graphical modellerin joint probability'sini tahmin etme - gösteriyoruz."
- Seq2Seq modelleri doğası gereği sıraya duyarlıdır, ancak sıralama gibi görevler doğası gereği sıraya duyarlı değildir.
- Read-Process-Write, girdinin permutation-invariant embedding'ini oluşturur. Bu, bir LSTM Pointer Network'e beslenir.
- Eğitim sırasında olası sıralar üzerinde arama yaparak sırasız çıktıları ele alır. Bu biraz garip hissettiriyor...
Variational Lossy Autoencoder
"Representation learning, gözlemlenen verilerin belirli yönlerini, sınıflandırma gibi downstream görevlere uygun bir öğrenilmiş gösterimde açığa çıkarmayı amaçlar. Örneğin, 2D görüntüler için iyi bir gösterim, yalnızca global yapıyı tanımlayan ve detaylı doku hakkındaki bilgileri atan bir gösterim olabilir. Bu makalede, Variational Autoencoder (VAE) ile RNN, MADE ve PixelRNN/CNN gibi neural autoregressive modelleri birleştirerek bu tür global gösterimleri öğrenmek için basit ama ilkeli bir yöntem sunuyoruz. Önerdiğimiz VAE modeli, global latent code'un ne öğrenebileceği üzerinde kontrol sahibi olmamıza izin verir ve mimariye göre tasarlayarak, global latent code'un 2D görüntülerdeki doku gibi ilgisiz bilgileri atmasını zorlayabiliriz, böylece VAE verileri yalnızca kayıplı bir şekilde "otomatik kodlar". Ayrıca, hem prior distribution p(z) hem de decoding distribution p(x|z) olarak autoregressive modelleri kullanarak, VAE'lerin generative modeling performansını büyük ölçüde iyileştirebilir, MNIST, OMNIGLOT ve Caltech-101 Silhouettes density estimation görevlerinde yeni state-of-the-art sonuçlar elde edebiliriz."
- TODO
A Simple Neural Network Module for Relational Reasoning
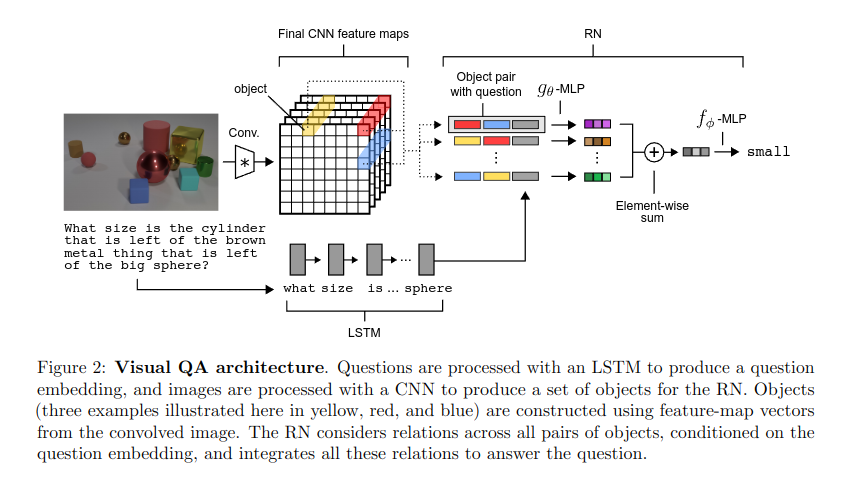
" Relational reasoning, genel olarak zeki davranışın merkezi bir bileşenidir, ancak neural networkler için öğrenmesi zor olduğu kanıtlanmıştır. Bu makalede, temelde relational reasoning'e bağlı olan problemleri çözmek için Relation Networks (RN)'i basit bir tak-çalıştır modülü olarak nasıl kullanacağımızı açıklıyoruz. RN ile güçlendirilmiş ağları üç görevde test ettik: CLEVR adında zorlu bir veri seti kullanarak visual question answering, ki burada state-of-the-art, insan üstü performansa ulaşıyoruz; bAbI görev seti kullanarak metin tabanlı soru cevaplama; ve dinamik fiziksel sistemler hakkında karmaşık akıl yürütme. Daha sonra, Sort-of-CLEVR adlı düzenlenmiş bir veri seti kullanarak, güçlü convolutional networkların ilişkisel soruları çözmek için genel bir kapasiteye sahip olmadığını, ancak RN'lerle güçlendirildiklerinde bu kapasiteyi kazanabileceklerini gösteriyoruz. Çalışmamız, bir RN modülü ile donatılmış derin öğrenme mimarisinin, varlıkları ve ilişkilerini örtük olarak nasıl keşfedebileceğini ve bunlar hakkında nasıl akıl yürütmeyi öğrenebileceğini göstermektedir. "
- Relational reasoning, farklı varlıklar veya bilgi parçaları arasındaki ilişkileri anlama, çıkarım yapma ve manipüle etme yeteneğidir.
- CLEVR visual reasoning görevinde insan üstü performans elde eder.
- RN'ler, bir NN'in fonksiyonel formunu, convolutional katmanların translational invariance yakalaması veya recurrent katmanların sequential dependencies yakalaması gibi, relational reasoning'in ortak özelliklerini yakalayacak şekilde kısıtlar.
- RN'ler bir nesne kümesi üzerinde çalışır ve aralarındaki (ikili) ilişkileri öğrenir.
Attention is All You Need
(Faydalı Açıklamalı Makale) (Orijinal Makale)
"Baskın sequence transduction modelleri, bir encoder ve decoder içeren karmaşık recurrent veya convolutional neural networkler'e dayanmaktadır. En iyi performans gösteren modeller ayrıca encoder ve decoder'ı bir attention mechanism aracılığıyla birbirine bağlar. Recurrence ve convolution'dan tamamen vazgeçerek, yalnızca attention mechanism'lerine dayalı yeni ve basit bir network mimarisi olan Transformer'ı öneriyoruz. İki makine çevirisi görevi üzerindeki deneyler gösteriyor ki..."
- Transformer mimarisi, RNN'lerin recurrent (ardışık) bağlantılarını ortadan kaldırır. Bu, GPU'larla verimli ve paralel eğitime olanak tanır.
- Self-attention mekanizması, modelin bir cümledeki farklı kelimelerin önemini, konumlarından bağımsız olarak ağırlıklandırmasını sağlar. Bu, uzun menzilli bağımlılıkları ve ilişkileri RNN'lerden daha etkili bir şekilde yakalamaya olanak tanır.
Kolmogorov Complexity and Algorithmic Randomness
Bu oldukça kapsamlı bir kitap ve ben sadece göz gezdirdim. Bunun yerine An Introduction to Kolmogorov Complexity and Its Applications'a bakmanızı öneririm.
- Kolmogorov Complexity, bir nesnedeki karmaşıklığın veya bilgi miktarının evrensel bir tanımıdır.
- Bu, bilinen alternatifler (semboller) listesinden bir nesneyi seçmek için iletilmesi gereken bilgi miktarı olan Shannon's Entropy'den farklıdır.
Neural Message Passing for Quantum Chemistry
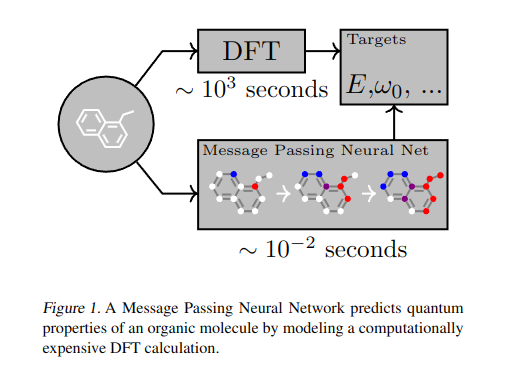
"Moleküller üzerinde supervised learning, kimya, ilaç keşfi ve malzeme bilimi için inanılmaz bir potansiyele sahiptir. Neyse ki, moleküler simetrilere karşı değişmez olan birkaç umut verici ve yakından ilişkili neural network modeli zaten literatürde tanımlanmıştır. Bu modeller, tüm giriş grafiğinin bir fonksiyonunu hesaplamak için bir message passing algoritması ve aggregation prosedürü öğrenir. Bu noktada, bir sonraki adım, bu genel yaklaşımın özellikle etkili bir varyantını bulmak ve ya onları çözene kadar ya da yaklaşımın sınırlarına ulaşana kadar kimyasal tahmin benchmark'larına uygulamaktır. Bu makalede, mevcut modelleri Message Passing Neural Networks (MPNNs) olarak adlandırdığımız tek bir ortak çerçevede yeniden formüle ediyoruz ve bu çerçeve içinde ek yeni varyasyonları keşfediyoruz. MPNN'leri kullanarak, önemli bir moleküler özellik tahmini benchmark'ında state of the art sonuçlar gösteriyoruz; bu sonuçlar, gelecekteki çalışmaların daha büyük moleküller veya daha doğru ground truth etiketlere sahip veri setlerine odaklanması gerektiğine inandığımız kadar güçlüdür."
- Message Passing Neural Networks (MPNNs), graf tabanlı veriler için çeşitli modellerin ortak özelliklerini soyutlar. Düğümler, komşularına yinelemeli olarak mesajlar gönderir, komşular bu mesajları toplar ve kendi durumlarını günceller. Son olarak, bir readout fonksiyonu, son düğüm durumlarını grafın global durumuna eşler.
- Grafın sırasına değişmez bir readout üretmek için set2set kullanır.
Relational Recurrent Neural Networks
"Hafıza tabanlı neural networkler, bilgiyi uzun süre hatırlama yeteneklerini kullanarak zamansal verileri modellerler. Ancak, hatırladıkları bilgilerle karmaşık ilişkisel muhakeme yapma yeteneğine sahip olup olmadıkları belirsizdir. Burada, öncelikle standart bellek mimarilerinin, varlıkların nasıl bağlandığını anlamayı içeren görevlerde - yani ilişkisel muhakeme içeren görevlerde - zorlanabileceğine dair sezgilerimizi doğruluyoruz. Daha sonra, hafızaların etkileşimini sağlamak için multi-head dot product attention kullanan yeni bir hafıza modülü - Relational Memory Core (RMC) - kullanarak bu eksiklikleri iyileştiriyoruz. Son olarak, RMC'yi sıralı bilgiler arasında daha yetenekli ilişkisel muhakemeden faydalanabilecek bir dizi görevde test ediyoruz ve RL alanlarında (örn. Mini PacMan), program değerlendirmesinde ve dil modellemesinde büyük kazanımlar gösteriyoruz, WikiText-103, Project Gutenberg ve GigaWord veri setlerinde state-of-the-art sonuçlara ulaşıyoruz."
- "Bir modelin bilgiyi bölümleyebileceği ve bölümlendirilmiş bilgi arasında etkileşimleri hesaplamayı öğrenebileceği bir mimari omurga."
- Relational Memory Core (RMC), satır bazlı hafızalar matrisi tutar. Güncellemeler, önceki hafızalar ve giriş üzerindeki attention aracılığıyla yapılır.
- Hafıza matrisi, bir 2D-LSTM'deki hücre durumları matrisi olarak görülebilir.
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
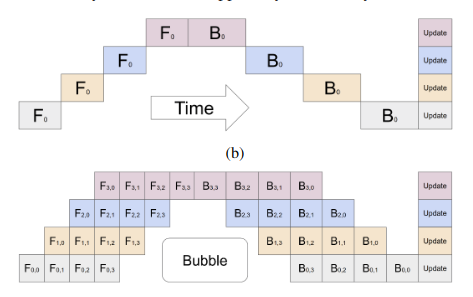
"Deep neural network kapasitesini artırmanın, çeşitli makine öğrenimi görevleri için model kalitesini iyileştirmenin etkili bir yaklaşımı olduğu bilinmektedir. Birçok durumda, model kapasitesini tek bir accelerator'ın bellek sınırının ötesine artırmak, özel algoritmalar veya altyapı geliştirmeyi gerektirmiştir. Bu çözümler genellikle mimariye özgüdür ve diğer görevlere aktarılamaz. Verimli ve görevden bağımsız model paralelliği ihtiyacını karşılamak için, katmanların bir dizisi olarak ifade edilebilen herhangi bir ağı ölçeklendirmeye olanak tanıyan bir pipeline parallelism kütüphanesi olan GPipe'ı tanıtıyoruz. GPipe, farklı katman alt dizilerini ayrı accelerator'larda pipeline haline getirerek, çeşitli farklı ağları devasa boyutlara verimli bir şekilde ölçeklendirme esnekliği sağlar. Üstelik GPipe, bir model birden fazla accelerator arasında bölündüğünde neredeyse doğrusal hızlanma sağlayan yeni bir batch-splitting pipelining algoritması kullanır. GPipe'ın avantajlarını, farklı ağ mimarilerine sahip iki farklı görevde büyük ölçekli neural network'leri eğiterek gösteriyoruz: (i) Image Classification: 557 milyon parametreli bir AmoebaNet modeli eğitiyoruz ve ImageNet-2012'de %84.4'lük bir top-1 doğruluk elde ediyoruz, (ii) Çok Dilli Neural Machine Translation: 100'den fazla dili kapsayan bir corpus üzerinde tek bir 6 milyar parametreli, 128 katmanlı Transformer modeli eğitiyoruz ve tüm ikili dillimodellere göre daha iyi kalite elde ediyoruz."
- Model boyutunu artırmak genellikle model performansını iyileştirir, ancak model büyümesi donanım büyümesini geçmektedir.
- GPipe, birden fazla accelerator üzerinde eğitim için synchronous stochastic gradient descent ve pipeline parallelism kullanan dağıtılmış bir makine öğrenimi kütüphanesidir.
- İleri geçiş: mini-batch'ler micro-batch'lere bölünür ve accelerator'lar arasında pipeline'lanır. Geri geçiş: gradientler micro-batch'ler arasında biriktirilir.
Scaling Laws for Neural Language Models
"Neural language model performansı için ampirik scaling law'ları inceliyoruz. Kayıp (loss), model boyutu, veri seti boyutu ve eğitim için kullanılan compute miktarı ile bir power-law olarak ölçeklenir, bazı trendler yedi büyüklük mertebesinden fazlasını kapsar. Network genişliği veya derinliği gibi diğer mimari detayların geniş bir aralıkta minimal etkileri vardır. Basit denklemler, overfitting'in model/veri seti boyutuna bağlılığını ve eğitim hızının model boyutuna bağlılığını yönetir. Bu ilişkiler, sabit bir compute bütçesinin optimal tahsisini belirlememize olanak tanır. Daha büyük modeller önemli ölçüde daha sample-efficient'tır, öyle ki optimum compute-efficient eğitim, çok büyük modelleri nispeten mütevazı miktarda veri üzerinde eğitmeyi ve yakınsama öncesinde önemli ölçüde durdurmayı içerir."
- "Language modeling performansı, model boyutunu, veriyi ve compute'u uygun şekilde ölçeklendirdiğimizde yumuşak ve tahmin edilebilir bir şekilde gelişir."
- Language model (Transformer) performansı en güçlü şekilde ölçeğe bağlıdır: model boyutu, veri seti boyutu ve compute kaynakları.
- Performans, her ölçek faktörüyle yumuşak bir power-law ilişkisine sahiptir (bu, artan ölçekle azalan marjinal getiriler anlamına gelir).
- Performans, "birçok mimari ve optimizasyon hiper-parametresine çok zayıf bağlıdır."
- "Sonuçlarımız, daha büyük modellerin performanslarının daha iyi olmaya devam edeceğini ve ayrıca daha önce takdir edilenden çok daha sample-efficient olacağını güçlü bir şekilde göstermektedir. Büyük veri yerine büyük modeller daha önemli olabilir."
CS231n Convolutional Neural Networks for Visual Recognition
"Bu kurs, özellikle image classification olmak üzere, bu görevler için end-to-end modeller öğrenmeye odaklanarak deep learning mimarilerinin detaylarına derinlemesine bir bakıştır."
Ders notları, neural network'lerin temellerinin mükemmel bir açıklamasını içerir, örneğin: